


Artificial intelligence (AI) is rapidly transforming industries, governments, and society as a whole. As AI systems become more sophisticated and integrated into critical functions like healthcare, finance, legal systems, and autonomous vehicles, the quality, trustworthiness, and compliance of their training data have emerged as top concerns. The foundation of any AI model's performance is the data it's trained on. If that data is flawed, biased, or non-compliant with regulations, the resulting AI can produce unreliable, unfair, or even harmful outcomes.
Recent years have seen a surge in global privacy laws, most notably the European Union's General Data Protection Regulation (GDPR) and the EU AI Act. These regulations impose stringent requirements on how data is collected, processed, and documented.1 Non-compliance can result in significant legal risks, including lawsuits, fines, and reputational damage.
I have written a new white paper that explains how specialized data platforms can provide robust, scalable solutions for sourcing, validating, and managing compliant AI training data. This article provides an overview of OWN, a new platform designed specifically to facilitate compliant transactions between owners and buyers of data structured for AI training purposes.
The High Stakes of Training Data Quality
The quality of AI training data directly influences the accuracy, reliability, and fairness of AI models. High-quality data enables machine learning systems to learn patterns, make accurate predictions, and generalize effectively to new situations. Conversely, poor-quality or biased data can lead to erroneous conclusions, flawed predictions, and a loss of trust in AI systems. High-profile failures in AI – such as biased risk assessment tools or facial recognition systems with disparate error rates – have been traced back to deficiencies in training data.
The legal and ethical implications of using unauthorized or non-compliant data are significant. Unauthorized use of copyrighted material can constitute infringement, while breaches of data protection laws can result in severe penalties. Ethically, using data without proper consent undermines the rights of creators and individuals, eroding trust and potentially exploiting personal or sensitive information.
Trusted AI training data is not only about accuracy but also about diversity, representativeness, and contextual relevance. Well-balanced, diverse datasets help prevent bias and ensure that AI systems are fair and effective across different groups and scenarios. Transparency in data collection, annotation, and documentation further boosts user confidence and perceptions of fairness. In critical fields like healthcare and finance, poor data quality can lead to suboptimal or even harmful decisions, highlighting the importance of data integrity and transparency.
The Booming Market for AI Training Data
The global AI training data market is experiencing explosive growth. In 2024, the core data collection market was valued at approximately $3.8 billion, with projections indicating it could reach $17 billion by 2030.2 When including licensed content and integrated data solutions, the total addressable market is expected to exceed $20 billion by the end of the decade and could reach $30–$40 billion by 2035. This growth is driven by the increasing demand for high-quality, diverse datasets needed to train complex AI systems across industries.
The scale of data required for training state-of-the-art AI models necessitates the adoption of automation, advanced annotation tools, synthetic data generation, and efficient data management platforms. Scalable AI training solutions reduce manual effort, accelerate model development, and lower data preparation costs, enabling organizations to keep pace with the rapid evolution of AI technologies.
Training Data: The Backbone of Modern AI Solutions
AI training data is essential across a wide range of applications.3 AI agents – such as chatbots, workflow automation tools, and cybersecurity agents – rely on data from user interactions, historical cases, and operational contexts to learn and improve their performance. Natural language processing (NLP) applications, including language translation, sentiment analysis, chatbots, and voice assistants, depend on large datasets of human language to understand and generate text or speech effectively.
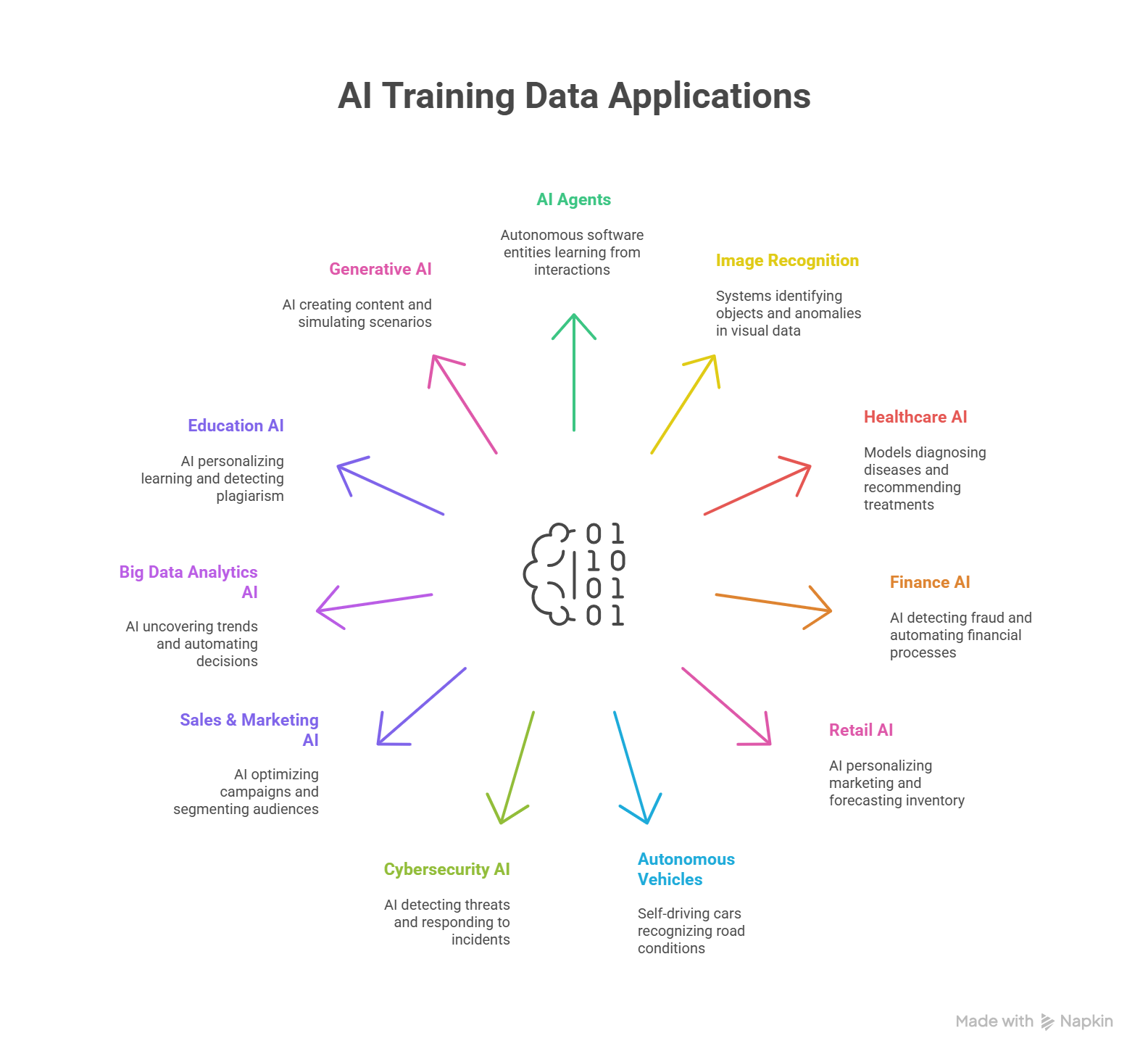
Image and video recognition systems, used in facial recognition, medical imaging, autonomous vehicles, and security surveillance, require annotated visual data to accurately identify objects, people, or anomalies. In healthcare, AI models are trained on patient records, clinical notes, and labeled scans to detect diseases and recommend treatments. In finance, historical transaction records, market data, and labeled financial events power fraud detection, algorithmic trading, credit scoring, and claims automation.
Retail and e-commerce platforms rely on purchase histories, browsing data, and product metadata to build recommendation engines, personalize marketing, and forecast inventory needs. Autonomous vehicles use sensor data – such as camera, radar, and lidar inputs – along with annotated driving scenarios to recognize road conditions, obstacles, and traffic signs. Cybersecurity applications are trained on logs of network activity, attack patterns, and labeled incidents to protect systems effectively.
Sales and marketing efforts leverage customer data, engagement metrics, and historical campaign results to optimize audience segmentation and campaign performance. Big data analytics across various industries rely on massive datasets to uncover trends, make predictions, and automate decision-making. In education, personalized learning platforms and plagiarism detection tools are trained on student performance data, educational content, and writing samples. Generative AI models, used for content creation – including text, images, and code – require diverse datasets to produce realistic and relevant outputs.
Across all these domains, high-quality, well-annotated training data is crucial to ensure AI systems operate accurately, fairly, and effectively in real-world scenarios.
The OWN Data Platform: Delivering Compliant AI Training Data at Scale
Amid the growing demand for AI training data and the evolving regulatory landscape, the OWN platform stands out as a unique and timely solution. OWN integrates GDPR-grade compliance, EU-based cloud infrastructure, and a dual-facing architecture that serves both individual and enterprise data providers.
OWN's commitment to compliance is evident in its use of data centers located in Germany, which helps mitigate concerns about extraterritorial data laws and simplifies cross-border compliance. The platform automates compliance checks, anonymization, and data quality checks, ensuring that every dataset is validated against EU regulations before it becomes available for licensing.
A key feature of the OWN platform is its flexible, decentralized storage approach. Data providers can keep their files on their existing storage – such as an S3 bucket, Azure Blob Storage, or, for private individuals, a Dropbox account – and only transfer data to OWN's secure German servers when they choose. This approach is ideal for organizations that need to protect sensitive or proprietary information, such as hospitals, banks, and public agencies. By defaulting to decentralized storage and letting providers decide where their data resides, OWN minimizes privacy risks and adheres to the strictest data protection regulations.
OWN's dual service model empowers both individuals and enterprises as data providers. Individuals retain control over their data, benefit from revenue-sharing opportunities, and manage their consent through intuitive tools. Enterprises gain access to a scalable, compliant data marketplace, enabling them to source high-quality training data without compromising on legal or ethical standards.
Best Practices for Trusted AI Training Data
The white paper outlines several best practices for organizations and data providers seeking to build and maintain trusted AI training data systems:
Compliance with Regulations: Ensure that all data collection, processing, and documentation practices adhere to relevant regulations, such as GDPR and the EU AI Act.
Data Quality and Diversity: Source data that is accurate, diverse, and representative of the scenarios the AI will encounter. Regularly update and rebalance datasets to mitigate bias and improve performance.
Transparency and Documentation: Provide clear information about data sources, annotation processes, and data quality checks. Transparent labeling and documentation foster trust and enable users to make informed decisions about AI outputs.
Privacy and Consent Management: Implement robust consent management systems, allowing individuals to control how their data is used. Ensure that data anonymization and encryption are applied where necessary.
Scalability and Automation: Leverage automation, advanced annotation tools, and synthetic data generation to scale data preparation and management efficiently.
Collaboration and Control: Enable decentralized data storage and flexible data sharing models, allowing organizations to maintain control over sensitive information while benefiting from collaborative AI development.
Conclusion
The rapid advancement of AI technologies and the increasing complexity of global privacy laws have made trusted, compliant training data more important than ever. High-quality training data is essential for AI systems to operate accurately, fairly, and effectively in real-world scenarios. By following best practices and leveraging platforms like OWN, organizations can ensure they have access to the high-quality, compliant training data they need to drive innovation and growth.
The full white paper can be downloaded here: https://owndata.io/whitepaper

References
https://gdprlocal.com/how-the-eu-ai-act-complements-gdpr-a-compliance-guide/
https://www.grandviewresearch.com/industry-analysis/data-collection labeling-market
Vogel, Paul. Training of AI Systems: Privacy, Data Protection and Data- driven Technologies (2024).
Sharing my article on a related topic
https://open.substack.com/pub/pramodhmallipatna/p/from-fair-use-to-data-moats-the-shifting